What is circuit sparsity?
Circuit sparsity is the idea that large neural networks do not need every neuron
and connection active all the time. Instead, only a small, relevant subset of the
model activates for a given input. These selective pathways are called circuits.
Like a brain—or a company—not every part is involved in every task.
Circuit-sparsity Toolkit for Programmers
OpenAI has released a research toolkit called circuit-sparsity, designed to make these internal circuits easier to identify and understand. The release includes a 0.4B parameter sparse model on Hugging Face and a full supporting codebase on GitHub.
In recent work, OpenAI released a research toolkit called circuit-sparsity,
designed to make these internal circuits easier to identify and understand.
The release includes a 0.4B parameter sparse model on Hugging Face
and a full supporting codebase on GitHub.
Key innovation
Unlike traditional post-training pruning, these models are trained with sparsity
enforced directly during optimization. In the sparsest versions, only about
1 in 1,000 weights remain nonzero while preserving functionality.
This extreme sparsity makes the internal computational mechanisms—circuits—far
easier to isolate, visualize, and reason about.
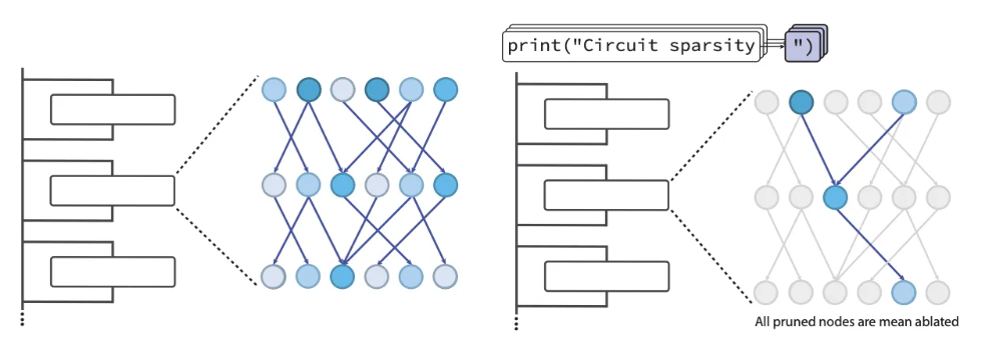
What are sparse circuits?
Circuits are defined at a very granular level: individual neurons, attention
channels, attention heads, and the specific connections between them. The approach
was tested on 20 simple Python coding tasks, such as correctly closing quotes
or tracking bracket nesting depth.
In sparse models, the discovered circuits were roughly 16× smaller than
those found in traditional dense models, while achieving similar performance.
Concrete examples
-
Quote-closing circuit: Uses just 12 nodes and 9 edges. One stage detects
and classifies quote types, and an attention head copies the correct closing quote.
-
Bracket-counting circuit: Tracks nesting depth by averaging signals from
multiple bracket-detecting neurons across context.
Bridging sparse and dense models
The toolkit introduces encoder–decoder bridge mechanisms that map activations
between sparse and dense models. This allows researchers to manipulate interpretable
features in sparse models and transfer those changes into standard dense systems.
This bridge creates a practical connection between interpretability research
and real-world, production-scale AI models.
Released resources
The circuit-sparsity release includes a 0.4B parameter model under
Apache 2.0, along with task definitions, circuit visualization tools,
and full research code.